
From Prompt Engineering to Context Engineering: A New Era in AI Prompting
- Alick Mouriesse

- Jul 7
- 24 min read
Updated: Jul 11
In the fast-evolving world of AI, the way we talk to large language models (LLMs) is changing. Not long ago, the focus was on prompt engineering, crafting the perfect prompt (question or instruction) to coax the best answer from AI. Now, an emerging concept called Context Engineering is taking center stage. This shift recognizes that giving an AI more and better context (background information, relevant data, roles, etc.) can be even more powerful than just cleverly wording a prompt.

In simple terms, prompt engineering is about how to ask, whereas context engineering is about what information the AI has when answering. This comprehensive report will explain what context engineering is, how it differs from traditional prompt engineering in scope, technical approach, and use cases, and why many experts see it as the next evolution in AI interaction.
We’ll use accessible definitions, real-world examples, and a clear comparison table to make these ideas beginner-friendly. Finally, we’ll see how University 365’s UP Method (University 365 Prompting) fits into this new paradigm, elevating prompting by embedding roles, user intent, and layered context in line with the latest AI best practices.
Alick Mouriesse https://www.linkedin.com/in/mouriesse/ https://x.com/MouriesseAlick
A U365 5MTS Microlearning 5 MINUTES TO SUCCESS
Report |
From Prompt Engineering
To Context Engineering
PLAN
Prompt Engineering: Crafting Effective Prompts
Key traits of Prompt Engineering:
Context Engineering: Designing the AI’s Environment
What counts as “context”?
The many components of context engineering.
Key traits of Context Engineering
Example – Scheduling Assistant:
Key Differences Between Prompt Engineering and Context Engineering
Prompt Engineering vs. Context Engineering – A Comparison
The Evolution: Why Context Engineering Is the New Frontier
How Big Is a Context Window? What “A Million Tokens” Really Means
University 365’s UP Method: A Case Study in Context Engineering
Context Layer
Role Layer
User Persona Layer
Audience Persona Layer
Task Prompt itself
Conclusion & Summary

Prompt Engineering: Crafting Effective Prompts
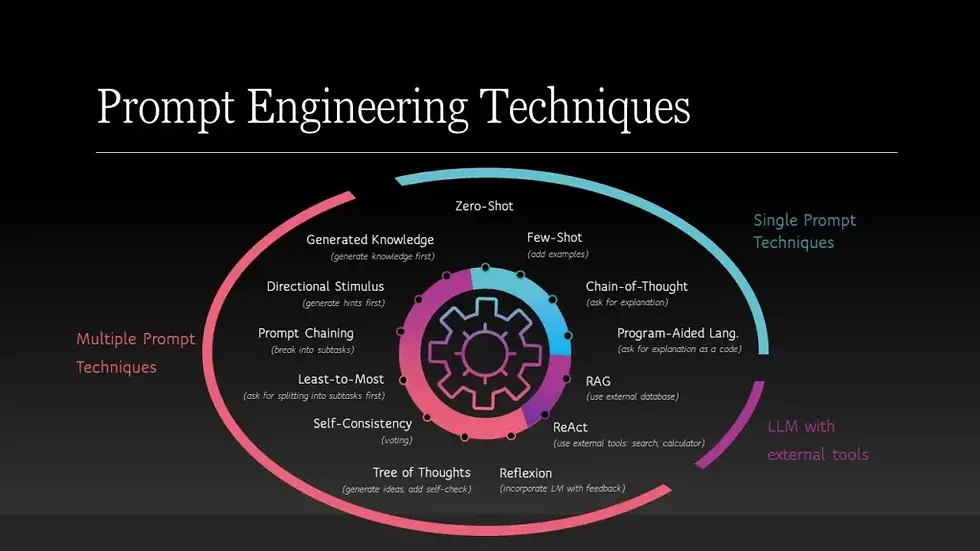
Prompt Engineering is the original skill of interacting with LLMs. It involves writing clear, targeted instructions or questions – often in a single prompt text, to guide the model’s output. A classic prompt-engineering trick might be giving the AI a role or style (e.g. “You are an expert travel guide. Describe the sights in Paris...”) or providing a couple of examples and then asking a question.
The goal is to get a specific desired response from the model with one well-crafted prompt.
You tweak wording, format, or add hints until the AI “gets it.”
In essence, prompt engineering is like asking a question in just the right way. It’s a bit of an art,you might experiment with phrasing, ask the model to follow certain steps, or include examples, all within that single prompt text.
Prompt engineering came to prominence in 2022–2023, when people realized that how you ask an AI greatly affects the answer. This led to viral stories of “$300k prompt engineer” jobs and countless tips on writing better. For example, a prompt engineer might discover that saying “Explain this to me like I’m five” yields a simpler answer, or that starting with “Let’s think step by step” makes the AI reason better. These techniques were invaluable for one-off queries or creative tasks (like “Write a tweet in the style of Shakespeare”).
Key traits of Prompt Engineering:
Focus: The focus is on the immediate instruction given to the model. You concentrate on wording and clarity within one conversation turn.
Scope: It typically operates on a single input-output interaction. Each prompt is crafted for a specific question/task, often without long-term memory of past prompts.
Technical Function: Prompt engineering doesn’t require special tools beyond the AI interface, it’s mostly wordsmithing. You might include a few examples (few-shot learning) or formatting cues, but you are not fundamentally altering how the AI system works.
Use Cases: Prompt engineering shines in one-off or short tasks: e.g. getting a well-written paragraph, a code snippet, a translation, or a quick answer. It’s great for creative generation, copywriting variations, or ad-hoc Q&A. For instance, if you ask “Write a product description for a new eco-friendly water bottle in an upbeat, playful tone,” a prompt engineer’s job is to phrase that request just right to get the best result.
Despite its power, prompt engineering has limitations. It can feel like trial-and-error, if the result isn’t right, you tweak the prompt again. Also, a single prompt can only contain so much context. That’s where context engineering comes in, as we’ll see next.
If you're new to Prompt Engineering, we recommend starting with our comprehensive Lecture Series: Prompting 101.
Context Engineering:
Designing the AI’s Environment

If prompt engineering is about writing a great question, Context Engineering is about setting the stage for the AI before the question is even asked. It involves designing the entire context or environment that the LLM “sees” so that the model has all the information and background it needs to produce a great answer.
In other words, context engineering means curating what data, instructions, history, and tools are fed into the model’s context window (its working memory) alongside the user’s prompt.
One AI expert described it with a useful analogy: “Prompt engineering was like learning to ask really good questions. Context engineering is like being a librarian who decides what books someone has access to before they start asking questions. Instead of only optimizing how to ask, context engineers optimize what the AI has access to when it’s answering.
This can include things like long-term facts, policies, prior conversation history, relevant documents retrieved from a database, or even tools the AI can use. Essentially, context engineering frames the whole conversation and supplies the AI with a rich, structured set of information to work with.
What counts as “context”?
It’s much more than just the latest user question. Context can include: system instructions (the role or persona the AI should adopt), previous dialogue in the conversation (so the AI remembers what was already said), the user’s profile or preferences, knowledge bases or documents related to the query, and even definitions of tools the AI can use.
Modern AI systems can also plug in retrieval, for example, finding relevant paragraphs from company manuals or academic papers and inserting them into the prompt. All of this becomes part of the AI’s input.
If prompt engineering is about writing a great sentence, context engineering is about assembling an entire dossier for the AI.
The many components of context engineering.
Instead of just a single prompt string, context engineering provides an LLM with multiple layers of information: system instructions (roles/rules), the user’s query, conversation history, long-term knowledge, retrieved documents, available tools or functions, and even desired output formats. All these pieces together form the context that the model uses to generate its answer.
Key traits of Context Engineering:
Focus: The focus is on the architecture of information given to the model. A context engineer asks: What does the AI need to know to do this task well? It’s as much about providing data and guidance as it is about the exact wording of the user’s question.
Scope: Context engineering operates at a higher scope, spanning multiple interactions and data sources. It treats the AI session as a persistent, dynamic system. For example, a context-engineered solution for a customer support chatbot would ensure the bot has the company’s FAQ, the customer’s account info, and conversation history all in context every time it answers.
Technical Function: Context engineering is more technical and system-oriented. It may involve tools like memory databases, retrieval algorithms, or API calls. Context engineers “curate, structure, and inject” information into the LLM’s input in an optimal way. They might use system messages (hidden instructions that set the AI’s role and rules), dynamic retrieval of documents (so the AI stays factual), tool use (allowing the AI to call external functions like web search or calculators), and formatting techniques (e.g. summarizing long text to fit token limits). In short, context engineering is akin to designing the AI’s working memory and thought process, not just a single prompt string.
Use Cases: Context engineering is crucial for complex, multi-turn, or production-level AI applications Whenever consistency, reliability, or scale is needed, simple prompts aren’t enough. Examples include:
AI assistants/agents with memory: For example, a coding assistant that remembers what you’ve done in a project across many queries, or a personal AI that remembers your preferences over time.
Customer support chatbots: They must pull in account details and policy documents so they answer accurately without hallucinating. Context engineering ensures the bot always has the right facts on hand.
LLM-based applications with tools: For instance, an AI that can fetch real-time data (weather, stock info, etc.) needs context engineering to know when and how to use those tools and how to integrate the results into its answers.
Multi-step workflows: If an AI needs to carry out instructions over several steps or maintain a long conversation (say, a tutoring system that tracks a student’s progress), context engineering handles the ongoing state and avoids the AI “forgetting” earlier details.
Enterprise use at scale: In business settings, you want AI outputs to stay consistent in tone and policy over thousands of queries. Context engineering provides that by centralizing things like company facts, style guides, and compliance rules into the context every time.
To illustrate the difference, let’s look at a beginner-friendly example of prompt vs. context engineering in action:
Example – Scheduling Assistant:
Imagine you’re building an AI assistant to schedule meetings via email. A prompt-engineered solution might simply take an incoming email like: “Hey, are you free for a quick sync tomorrow?” and feed it to the LLM with a prompt like: “You are an scheduling assistant. Reply to the email politely with availability.” The output might be a generic response: “Thank you for your message. Tomorrow works for me. What time were you thinking?” – technically correct, but not very smart or helpful in context.
Now consider a context-engineered approach: Before the AI even generates a reply, we gather relevant context for the task. We retrieve the user’s calendar (which shows they are fully booked tomorrow), pull up past emails with this colleague (to maintain an informal tone), note who the colleague is (a key project partner), and even load a tool that can send a calendar invite.
All these pieces, schedule data, relationship info, tools, are added to the AI’s context alongside the original email. The AI then gets a much richer prompt, perhaps structured as:
System message: (“You are a helpful personal assistant with access to the user’s calendar and email tools…”), User message: (“[The colleague’s email]”), Context: (“Calendar shows no free slots on requested day; prior correspondence tone is casual; colleague = project manager; you have a send_invite function”). With this full context, the AI’s reply becomes something like: “Hey Jim! Tomorrow’s totally packed on my end – back-to-back meetings all day. I’m free Thursday morning though. I’ve sent over a calendar invite for 10am Thursday; let me know if that works for you!”.
The difference is night and day.
The AI didn’t magically become smarter; it was the context that enabled a better response. This example highlights a key point: many failures of AI assistants are not due to a bad model or prompt, but due to missing or poor context.
By engineering the context, we set the AI up for success.
Context engineering doesn’t replace prompt engineering; it augments it.
In short, context engineering doesn’t replace prompt engineering; it augments it. You still need good instructions, but they’re embedded in a richer information environment. The prompt itself might even be simpler because the AI already has what it needs.
A helpful way to think of their relationship is: “Prompt engineering is what you do inside the model’s input window; context engineering is about deciding what goes into that window in the first place.”
Key Differences Between
Prompt Engineering and Context Engineering

Let’s break down the differences in clear terms. Table 1 below compares prompt vs. context engineering on several dimensions (scope, technical focus, typical use, etc.). We’ll then discuss how context engineering is essentially an evolution of prompt engineering as LLM usage matures.
Table 1: Prompt Engineering vs. Context Engineering – A Comparison
Aspect | Prompt Engineering | Context Engineering |
Definition & Focus | Crafting a single prompt (instruction or query) to guide an immediate response. Focuses on wording and clarity of that prompt. “What exactly should I ask the model right now?” | Designing the entire context the model sees, including background data, system roles, tools, and history. Focuses on providing all necessary information and structure for the model’s reasoning. “What information and setup does the model need to accomplish this task?” |
Scope | Narrow; operates on a single interaction (one prompt → one response). Each prompt is a standalone attempt, often with no memory of previous prompts. | Broad; operates across multiple inputs and persistent state. Encompasses the whole conversation/session and beyond (e.g. long-term memory). Considers everything the model sees or can use, not just the user’s latest question. |
Technical Function | Primarily text crafting. May involve a bit of formatting or including examples in the prompt, but no complex pipeline. Can be done with just a chat box and creativity. Tools: None or minimal (maybe copy-paste examples). | Closer to systems design or architecture for LLMs. Involves managing memory, retrieving external info, using APIs or tools, layering system and user prompts, etc. Often requires frameworks or code to assemble context dynamically. Tools: May use databases (for long-term knowledge), retrieval algorithms (RAG - Retrieval-Augmented Generation, is an AI framework that combines the strengths of traditional information retrieval systems (such as search and databases) with the capabilities of LLMs) to pull in relevant text, vector embeddings, orchestrators like LangChain (LangChain is a framework for developing applications powered by LLM), or custom pipelines. |
Use Cases & Examples | Great for one-off tasks and creative prompts. For example: generating a poem, translating a paragraph, asking a single factual question, or getting code for a known problem. Also used in quick demos and experiments where you just need a single good answer. | Essential for complex, long-running or high-stakes applications. Examples: virtual assistants that carry on extended conversations, customer service bots using a knowledge base, AI tutors tracking student progress, coding copilots that manage large code context, or any production AI service that must remain consistent and accurate over time. |
Consistency & Scale | Hit-or-miss; not easily scalable. Quality can vary with phrasing, and each new prompt might require tweaking. If you need 1000 answers, you may have to adjust prompts frequently for consistency. Harder to enforce a unified style or policy across many outputs. | Designed for consistency and reuse at scale. By injecting the same context (policies, style guidelines, facts) every time, it ensures the 1000th answer is as on-point as the 1st. Easier to enforce standards (the context carries corporate tone, legal rules, etc. every time). Built with multiple users and long-term reliability in mind. |
Failure Modes | If done poorly: the model output might be irrelevant, incorrect in tone, or ignores parts of the instruction. Tends to fail in obvious ways (e.g. you ask for an explanation and get a brief answer because the prompt wasn’t clear enough). | If done poorly: the whole system can go awry – the model might get confused by irrelevant or poorly formatted context, “forget” the conversation goal, hallucinate due to missing info, or misuse a tool. Failures can be subtle: e.g. a crucial document wasn’t retrieved, leading to a confident but wrong answer. Debugging requires inspecting what context was provided, not just the last prompt. |
Mindset | Think of it as creative writing or copywriting for AI. Emphasis on phrasing and immediate result. It’s about speaking to the AI effectively in a given moment. | Think of it as system architecture for AI interactions. Emphasis on designing information flows. It’s about making the AI an effective problem-solver by controlling what it “sees” and remembers. You’re essentially managing the AI’s working environment. |
As the table shows, prompt engineering is actually a subset of context engineering. You still need to write good instructions (that part doesn’t go away), but in context engineering those instructions are just one piece of a larger puzzle.
A context engineer will decide, in addition to the prompt itself, things like: which knowledge to retrieve, which persona or role the AI should assume, what prior interactions to include or summarize, and what tools or functions the AI should have.
In fact, one commentator neatly put it:
“Prompt engineering focuses on what you say to the model; context engineering focuses on what the model knows when you say it – and why it should care.”
In practice, prompt engineering skills live inside a context engineering. By designing a good context, you make prompt crafting easier and more reliable.
For example, if an AI is burying your carefully written prompt under a heap of irrelevant text (like lengthy prior messages or extraneous retrieved info), even the best prompt might fail, context engineering would fix that by structuring the conversation or trimming irrelevant context.
In summary, prompt engineering gets you a good first result; context engineering lets you get good results consistently, at scale.
The Evolution:
Why Context Engineering Is the New Frontier

It’s clear that context engineering expands the scope of prompt design, and the AI community is embracing it as the next step in working with LLMs. In 2023, prompt engineering was the hot topic (as mentioned, everyone was learning how to write clever prompts).
But as LLMs have improved and their context windows (the amount of text they can handle at once) have grown exponentially, from a few thousand tokens to now hundreds of thousands or more, the strategy has shifted.
We are no longer as constrained to one neat prompt; we can feed entire documents or knowledge bases into the model’s context. This unlocks new possibilities: instead of trying to make the AI guess or be extremely generalized, we can just give it the relevant information directly and let it work from that.
As one practitioner put it, “It’s a fundamental shift from optimizing sentences to optimizing knowledge.” Many experts now argue that “the new skill in AI is not prompting, it’s context engineering.”
In other words, providing the right supporting information to the model matters more than coming up with magical wording.
Tobi Lütke, the CEO of Shopify, coined and popularized the term “Context Engineering.” He explained that it “describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM”.
This idea was quickly echoed by AI leaders.
For example, Andrej Karpathy (former director of AI at Tesla and a prominent AI researcher) agreed wholeheartedly, saying that in any real-world AI application, “context engineering is the delicate art and science of filling the context window with just the right information for the next step… Doing this well is highly non-trivial.”
What prompted this shift?
One reason is that as people built more complex AI agents and applications, they discovered that failures often came from missing or poorly managed context rather than a lack of prompt cleverness. In fact, with advanced models, if something goes wrong, developers now ask: Was the model given the proper context?
Often the model could have produced a correct answer if only it had been fed the right information. This has led to a focus on data retrieval, memory management, and tool use around LLMs, all elements of context engineering.
Industry and academia are responding by developing tools and frameworks to make context engineering easier.
For instance, LLM orchestration frameworks like LangChain provide ways to integrate databases, APIs, and logic for assembling prompts dynamically, effectively making context engineering a first-class citizen in AI development. (The LangChain team even published a blog post titled “The rise of ‘context engineering’”, emphasizing that this is becoming the most important skill for AI engineers.)
Other platforms and libraries (for memory storage, conversation summarization, etc.) are emerging to support the context-centric approach.
Even without deep technical knowledge, the takeaway is: the AI field is moving beyond just talking to models cleverly, and toward building an information ecosystem around models so they can perform intelligently.
To put it succinctly, Prompt engineering was Phase 1: teaching us how to speak to AI. Context engineering is Phase 2: teaching us how to think with AI, by making sure the AI has the right knowledge, context and tools to truly collaborate.
It’s a broader, more strategic mindset. As Dharmesh Shah of HubSpot wrote, “Prompting tells the model how to think, but context engineering gives the model the training and tools to get the job done.”
In practice, both skills work together, but context engineering is increasingly where the real innovation, and value, is found.
How Big Is a Context Window?
What “A Million Tokens” Really Means

As of July 2025, here are the context window sizes for leading LLMs—and what they mean in everyday terms:
ChatGPT (Open AI GPT‑4.1)
API version: up to 1 million tokens
ChatGPT interface (Plus/Pro users): limited to 128K tokens
For Open AI 1 million tokens ≈ ~750,000 words. Roughly equivalent to 1,500 full-length novel pages (at ~500 pages each - ~3 novels ).
The 128K version is still huge: ~96,000 words, or about 192 typical novel pages.
Claude (Anthropic)
Default: 200K tokens
Enterprise tier: up to 1 million tokens
For Anthropic 200K tokens ≈ ~150,000 words or 300 pages of text.
At 1 million tokens, it’s about 1.5 million words, or ~3,000 pages—over 6 full novels.
Gemini (Google)
Gemini 2.5 Pro (released Mar 2025): 1 million tokens
Gemini 1.5 Pro (developer preview): up to 2 million tokens
For Google 1 million tokens ≈ ~750,000 words → ~1,500 pages (~3 novels).
2 million tokens ≈ ~1.5 million words → ~3,000 pages (≈6–7 novels).
Why It's Important
A larger context window lets an LLM:
Read and process entire books, codebases, or long legal documents in one go.
Maintain coherence over extended conversations, without losing earlier details.
Access embedded documents, memory, or data sources all at once, improving accuracy and personalization.
Summary Table of Context Window for major LLMs
Model / Tier | Tokens | Words (≈0.75 per token) | Pages (≈500 words/page) | Equivalent Novels |
ChatGPT API (GPT‑4.1) | 1 000 000 | 750 000 | 1 500 | ~3 |
ChatGPT Interface | 128 000 | 96 000 | 192 | ~0.4 |
Claude Default | 200 000 | 150 000 | 300 | ~0.6 |
Claude Enterprise | 1 000 000 | 750 000 | 1 500 | ~3 |
Gemini 2.5 Pro | 1 000 000 | 750 000 | 1 500 | ~3 |
Gemini 1.5 Pro (preview) | 2 000 000 | 1 500 000 | 3 000 | ~6 |
So, when models support hundreds of thousands or even millions of tokens, that translates to processing the equivalent of thousands of pages, as if the AI has immediate access to entire books or extensive project files. This vastly enhances its ability to give accurate, coherent, and bespoke responses, truly realizing the power of context engineering.
University 365’s UP Method:
A Case Study in Context Engineering

To see context engineering in action, let’s look at University 365’s UP Method (which stands for “University 365 Prompting”).
UP is a framework developed to improve AI prompts in educational and business settings by structuring them into multiple layered contexts.
In essence, it takes the static parts of a prompt, the pieces that don’t change every time, and turns them into reusable context modules, while leaving only the specific task as the variable portion.
This modular approach is a textbook example of context engineering, because it focuses on supplying the AI with rich context (roles, facts, personas) before the actual question is asked.
How does the UP Method work? It organizes prompts into four key layers of context (plus the task).
These layers are: Context, Role, User Persona, and Audience Persona:
Context Layer: Factual background and data needed for the task. For example, a company’s profile, product details, or any relevant facts. This ensures the AI has correct information on hand (preventing factual errors or “drift”).
Role Layer: The professional role or perspective the AI should adopt. For instance, “Act as a Marketing Director” or “You are a career counselor.” This sets the tone and domain expertise for the response. It’s like a persistent system instruction about who the AI is pretending to be.
User Persona Layer: Details about the user or speaker who is asking the AI. In an enterprise scenario, this could be the user’s position, goals, or even personality (e.g. the user is Sam Altman, CEO of OpenAI, in the example below). By specifying the user persona, the AI’s answers can be aligned with that person’s intent or voice. Think of this as modeling the user’s intent and point of view explicitly.
Audience Persona Layer: Information about the target audience or end reader of the AI’s output. For instance, whether the answer will be read by a technical team, by the board of directors, or by new students, etc. This helps the AI tailor the content and complexity appropriately.
Finally, you have the Task Prompt itself, which can now be relatively concise, because all the supporting context is provided by those layered files. The task prompt describes what needs to be done right now (e.g. “Draft a 90-day marketing launch plan for our new product and then write an email to the board summarizing it.”).
An example from University 365’s UP Method documentation makes it clear. Suppose an executive wants an AI to help plan a product launch. Using UP Method, they would prepare the context like so:
Context file: A PDF with the company’s background info (OpenAI_company_profile_v3.2.pdf).
Role file: A file defining the duties and style of a Marketing Director (role_OpenAI_marketing_director_v2.0.pdf).
User Persona file: A file describing the user as Sam Altman, CEO of OpenAI (persona_OpenAI_ceo_SamAltman_v1.1.pdf – containing Sam’s perspective and priorities).
Audience Persona file: A file describing the Board of Directors as the audience (persona_OpenAI_board_v1.0.pdf – outlining what the board cares about, level of formality, etc.).
With these in place, the Task Prompt might simply say: “As OpenAI’s Marketing Director, create a 90-day omnichannel launch plan for our new AI-powered Learning Management System. Then draft an engaging email from Sam Altman to the Board, explaining this launch plan.” When the AI (ChatGPT or another LLM) receives this, along with all those context files, it can produce a highly specific answer: a detailed launch plan document and a CEO-styled email to the board, all consistent with OpenAI’s actual strategy and tone. The user didn’t have to stuff all the facts or roles into one prompt – they were engineered into the context via the UP Method’s layers.
Crucially, if you later have a related task, you can reuse those context layers.
For example, if next you want an email to the financial department instead of the board, you keep the same Context, Role, and User Persona layers, and just swap the Audience Persona to a “Financial Department” profile and adjust the task prompt. This modularity is the hallmark of context engineering, it’s adaptable and maintainable.
A team can maintain a library of approved context files (company facts, predefined roles, personas for typical users and audiences), and assemble them as needed.
This saves time and ensures every prompt is consistent in voice and accuracy. In fact, University 365 reports that the UP Method cut their prompt development time by ~70% and reduced token usage by ~40%, while eliminating compliance errors in outputs. Those metrics underline how effective context engineering can be in a real workflow.
The UP Method shows how context engineering elevates prompting: by embedding role-based context (the AI’s role and the situation facts), modeling user intent and identity (persona), and layering everything in a structured way, you get much more robust results than a plain prompt. It aligns perfectly with the broader shift in LLM usage, treating prompts not as one-off strings, but as compositions of reusable pieces that carry strategic knowledge.
The approach is “prompt engineering, industrialized”, turning ad-hoc prompts into audit-able, version-controlled, and shareable building blocks. This is especially important for educators and enterprises: it ensures that AI responses honor the correct context every time (e.g., always the right facts, the right tone for the audience, and the user’s true intent).
In summary, University 365’s UP Method is a concrete example of context engineering in practice, it embodies the new paradigm by demonstrating how separating context from prompt leads to better AI outcomes.
If you want to learn more about the UP Method, read this Micro-learning Lecture : The UP Method (University-365 Prompting) - The new gold standard for prompt engineering
Conclusion and Summary
The rise of context engineering marks an important evolution in how we work with AI. To recap the key points and ensure clarity:
Prompt Engineering vs Context Engineering: Prompt engineering is about writing a single prompt effectively, it’s like asking a good question. Context engineering is about providing all the surrounding information and structure the AI needs, it’s like giving the AI an open-book exam instead of a blind test. Context engineering doesn’t replace prompt skills but builds on them, enabling more complex and reliable AI interactions.
Scope and Technical Differences: Prompt engineering treats each query in isolation, focusing on phrasing in that moment. Context engineering takes a broader view, managing persistent data (history, profiles, documents) and possibly integrating tools or external knowledge into the conversation. Technically, prompt engineering is something anyone can do in ChatGPT with careful wording, whereas context engineering often involves an architecture, using memory stores, retrieval (e.g. pulling info from a database), and orchestrating multiple prompt components. It’s more technical but yields a more tailored and controlled AI behavior.
Use Cases and Benefits: Prompt engineering works well for quick tasks and can be a fun, creative exercise (e.g. getting the AI to produce a witty poem). However, when you need consistent, accurate results across many queries or over time, context engineering is crucial. It shines in use cases like customer support bots, AI assistants with long conversations, or any system that must adhere to rules and context (like legal AI advisors or personalized learning tutors). By injecting the right context, we avoid common AI issues like hallucinations (making up facts) or incoherent replies, because the AI isn’t guessing, it’s referring to provided info.
Community Shift: The AI community, from researchers to industry leaders, increasingly views context engineering as the successor to prompt engineering. Terms like “the art of context” are being used to describe the real skill of working with advanced AI. This shift is visible in blogs, workshops, and tools that focus on how to feed the AI the right data. As models get larger context windows and we build more complex AI agents, knowing how to assemble and manage that context is becoming a key competency.
University 365’s UP Method: Aligning with the Future: The UP Method example demonstrates how an organization can formalize context engineering for its needs. By pre-defining roles, personas, and context files, University 365 ensures that any prompt sent to an AI is enriched with the proper background and intent. This is essentially context engineering as a repeatable framework. It shows how education and business can benefit: faster prompt creation, consistent tone and accuracy, and the ability to adapt prompts easily by swapping context layers. The UP Method encapsulates the principles of context engineering (modularity, role-based context, user intent modeling, and layered assembly) and highlights how moving beyond ad-hoc prompts can elevate the quality of AI outputs on a large scale.
In conclusion, Context Engineering broadens our approach to prompting AI. It’s about engineering the situation for the AI, not just the sentence we type.
By combining rich context with clear prompts, we can unlock more of an AI’s potential, getting responses that are correct, but also relevant, personalized, and reliable.
As AI systems become more integrated in education, business, and daily tools, mastering context engineering will be key to building AI solutions that truly understand our needs and operate safely within our constraints.
Summary – Key Takeaways:
Context is King: Rather than obsessing over the perfect wording, provide your AI with the right information and context. A well-prepared context often beats a cleverly worded prompt in delivering quality results.
Think Like an Architect: When designing AI interactions, think beyond one question, consider the whole environment. Ask yourself: What does the model need to know to do this well? This might include documents, examples, user preferences, or tools. Supplying these will guide the AI more effectively than any single sentence could.
Consistency and Scale: For reliable performance (especially in professional or educational settings), use context engineering techniques. Reuse context modules (facts, roles, personas) to ensure every answer follows the same facts and style. This way, your 100th answer will be just as on-point as the first.
UP Method: A Practical Example: University 365’s UP Method shows how to implement context engineering: break your prompt into layers (Context, Role, User Persona, Audience) and maintain those as separate files. Then your actual query can be simple, while the heavy context is loaded from those layers. This saves time and makes prompts much more powerful and personalized.
Empowering All Users: Whether you’re a student, teacher, developer, or business leader, understanding context engineering can help you get more out of AI. For non-technical users, this might simply mean providing more background to the AI (e.g., “Here is my class syllabus and notes, now answer this question…”). For technical builders, it means designing systems that feed the AI the right data at the right time. In both cases, the principle is the same: don’t just ask the AI for answers, give it the materials to build the best answer.
By moving from prompt engineering to context engineering, we are essentially teaching AI in a richer way, much like a teacher would provide students with textbooks and guidance, not just pop quiz questions.
This comprehensive approach is increasingly crucial as we integrate AI into real-world applications. It ensures AI systems are not only intelligent, but also informed, context-aware, and aligned with our goals. In the new era of AI prompting, how well we prepare the context will define how useful and trustworthy the AI’s responses can be.
Alick Mouriesse
University 365 https://www.linkedin.com/in/mouriesse/
Recommended Lecture Available For Free INSIDE U365


Discussions To Learn Deep Dive - Podcast
Click on the Youtube image below to start the Youtube Podcast.
cover more Dicusssions To Learn and Subscribe to D2L Youtube Channel ▶️ Visit the U365-D2L Youtube Channel
Do you have questions about that Publication? Or perhaps you want to check your understanding of it. Why not try playing for a minute while improving your memory? For all these exciting activities, consider asking U.Copilot, the University 365 AI Agent trained to help you engage with knowledge and guide you toward success. U.Copilot is always available, even while you're reading a publication, at the bottom right corner of your screen. You can Always find U.Copilot right at the bottom right corner of your screen, even while reading a Publication. Alternatively, vous can open a separate windows with U.Copilot : www.u365.me/ucopilot.
Try these prompts in U.Copilot:
I just finished reading the publication "Name of Publication", and I have some questions about it: Write your question.
I have just read the Publication "Name of Publication", and I would like your help in verifying my understanding. Please ask me five questions to assess my comprehension, and provide an evaluation out of 10, along with some guided advice to improve my knowledge.
Or try your own prompts to learn and have fun...
Are you a U365 member? Suggest a book you'd like to read in five minutes,and we’ll add it for you! |
Save a crazy amount of time with our 5 MINUTES TO SUCCESS (5MTS) formula.
5MTS is University 365's Microlearning formula to help you gain knowledge in a flash. If you would like to make a suggestion for a particular book that you would like to read in less than 5 minutes, simply let us know as a member of U365 by providing the book's details in the Human Chat located at the bottom left after you have logged in. Your request will be prioritized, and you will receive a notification as soon as the book is added to our catalogue.
NOT A MEMBER YET?



Comments